
In tabellen.htm werden Tabellen und Spalten des GTDS beschrieben und erläutert. Folgende Informationen sind zu finden:
Stimmt in "Herkunft" der Tabellenname mit dem Namen der Tabelle und der Spaltenname mit der Spalte überein so handelt es in der Regel sich um eine Spalte, die Informationen zum Gegenstand der Tabelle selbst enthält, während im anderen Fall die Information dazu dient, Beziehungen (Joins im Sinne von SQL) zu anderen Tabellen herzustellen.
Beispiel:
DIAGNOSETEXT in TUMOR gehört zu den Informationen über einen Tumor direkt. FK_PATIENTPAT_ID entspricht in der Tabelle PATIENT der PAT_ID und dient zum Verknüpfen (Join) von TUMOR und PATIENT.
Diese Information kann teilweise auch aus der Benennung der Spalte abgelesen werden: Spalten die mit FK... beginnen dienen der Verknüpfung mit anderen Tabellen. Dabei gibt der Bestandteil, der dem FK... folgt den Namen der anderen Tabelle an und wird gefolgt vom Spaltenname in der anderen Tabelle. Aufgrund historischer Entwicklungen in der Designphase sind diese Namen jedoch unter folgenden Bedingungen schwer zu lesen:
Aus dem gleichen Grund kann es vorkommen, daß mehrere Spalten einer Tabelle die gleiche Spalte in einer anderen Tabelle referenzieren. Zum Beispiel beziehen sich in HISTOLOGIE sowohl FK_TUMORFK_PATIENT als auch FK_VERLAUFFK_TUMO0 auf PAT_ID in PATIENT. Das Design-Tool ist in diesem Fall davon ausgegangen, daß der zugehörige Tumor zu einem anderen Patienten gehören könnte als zugehörige Verlaufsinformation, was selbstverständlich nicht der Fall sein kann. Häufig steht in der Beschreibung dann "aktuell kein Eintrag" oder ähnliches, um zu kennzeichnen, welche Spalten nicht benutzt werden.
Die Informationen zum Datentyp sind übrigens nicht hundertprozentig exakt, da die Tabellen nur teilweise automatisch gepflegt werden und dadurch z.B. Änderungen des Datentyps nicht sicher erfaßt werden.
Die selben Informationen zusätzlicher einiger weiterer Informationen sind in der Maske tudok_dd, zugänglich aus "Benutzer, Rechte, usw." erhältlich.
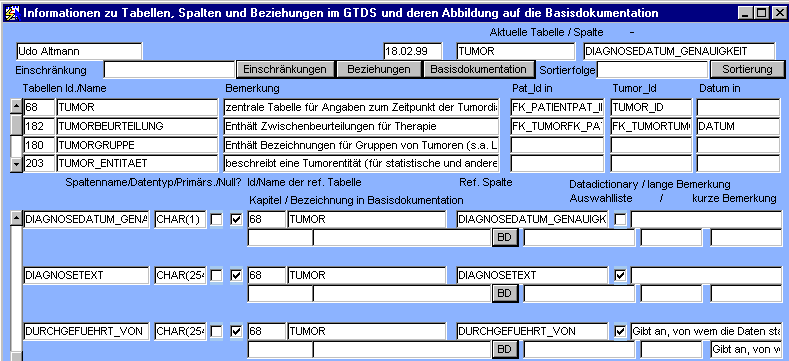
Zusätzlich enthält diese Tabelle Informationen darüber, welche Spalten Primärschlüssel (Identifier) der Tabelle bilden und welche Null-Werte enthalten dürfen, also nicht gefüllt werden müssen. Diese Informationen sind allerdings, da von eher untergeordneter Bedeutung für das Bilden von select-Statements, nicht gepflegt, also unzuverlässig. Die Spalte Data Dictionary kennzeichnet, ob eine Spalte im Data Dictionary enthalten sein soll. Das Data Dictionary ist eine speziellen Sichtweise, realisiert als View, zum Aufsuchen bestimmter Informationen und ist derzeit im Aufbau begriffen. Die Spalte KURZKOMMENTAR enthält derzeit die auf 254 Zeichen gekürzte Spaltenbeschreibung, um SQL-Suchen in den Beschreibungen durchführen zu können.
Sowohl dieses Skript, als auch die Masken greifen auf die Tabellen TUDOK_TABLES und TUDOK_SPALTEN zurück, die wie erwähnt, nach umfangreicheren Änderungen halbautomatisch gepflegt werden. Mit enthalten, aber nicht gepflegt, sind automatisch Informationen über die ReportWriter-Tabellen, beginnend mit SRW_, da diese unter der OPS$TUMSYS-Kennung installiert sind.